A un año del trágico accidente de la línea 12 del metro el equipo de Estado Abierto del INFO CDMX elaboró un reporte con información pública. En este post vamos a aprende a usar las API de datos abiertos (de CKAN) y analizar las solicitudes de información pública.
code
visualization
politics
spanish
Author
David Humberto Jiménez S.
Published
September 13, 2022
Modified
November 30, 2023
Solicitudes de … qué?
El 4 de julio de 2022 se presentó un informe de Solicitudes de Información Pública (SIP) sobre la Línea 12 del Metro en la Ciudad de México. En resumen, un tramo de la línea colapso por defectos en la construcción, las personas implicadas de su construcción están en puestos de gobierno y de toma de decisiones. Para sorpresa de nadie, los posibles implicados se están deslindando de responsabilidades y señalamientos.
Pero, el informe se realizó con base en las SIP del 3 de mayo del 2021 al 11 de mayo de 2022, es decir: sobre lo que preguntan las personas a las instituciones de la Ciudad de México. Para ver la presentación pueden ver el siguiente video y si quieren pueden leerlo aquí.
Y hasta ahí todo sin pena ni gloria: todo es trágico, la gente pide información y a se le deja esperando que alguien le responda. Clásico de una democracia, ¿verdad? Pues así era, hasta que “alguien” se enojó y regaño a dos comisionados del Instituto desde donde se realizó el informe. ¿Y la autonomía a’pá?
Si no me creen, vean este video donde en el pleno los comisionados, cofcofmachitoscofcof, continúan con la línea establecida por el gobierno, ofrecen otros datos (sello de esta era política): mayor número de solicitudes (porque evidentemente más preguntas significa más transparencia), y que más del 95% han sido respondidas.
¿Qué significa haber respondido una solicitud de transparencia? Más adelante hay un párrafo sobre algunos hallazgos sobre las respuestas de esta base de datos. Además, si conocen de transparencia saben que una posible respuesta es que esa institución no tiene esa información. En aproximadamente la mitad de los casos no sabemos qué respondió el sujeto obligado.
En fin, este no es un rant, este es un blog de datos y eso es lo que haremos. Dado que ya se publicaron las SIP que se utilizaron en el informe, vamos a replicar las gráficas y ver que otra cosa sale.
Análisis
Entonces, a mi me gusta llamar primero a las libraries que vamos a utilizar, luego los datos y empezar a explorar.
library(tm)
Loading required package: NLP
library(httr)
Attaching package: 'httr'
The following object is masked from 'package:NLP':
content
library(tidyr)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(plotly)
Loading required package: ggplot2
Attaching package: 'ggplot2'
The following object is masked from 'package:NLP':
annotate
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:httr':
config
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
The following objects are masked from 'package:base':
date, intersect, setdiff, union
Ahora, podemos hacer lo de siempre y descargar los datos, importarlos y limpiarlos. Pero, como el punto de todo esto es aprender a hacer cosas nuevas vamos a leer la API de los datos abiertos del INFO.
Así debe verse
Le damos clic en explorar
Nueva pantalla…
Y en el botón verde que dice “API de datos” le damos clic y se verá de la siguiente manera:
Ta-dá!
Seleccionamos lo que está subrayado (así como queda en el código de abajo) que es el enlace que necesitamos para “llamar” a los datos. Para revisar por qué hice esto pueden checar el trabajo de Alan Yeung
Debe salir 200 para saber que se logró llamar a la información, si sale otra cosa vean el blog ya mencionado. Ambas funciones, GET y status_code, son del paquete httr.
Por default la consulta tiene un límite de 100 observaciones, por eso a la url hay que agregarle el string &limit= donde el número es el total de observaciones que hay publicadas. Y del paquete jsonlite la función fromJSON nos permite obtener los datos (records). Y listo! Con estas instrucciones ya podemos utilizar todas los datasets que tiene publicados el INFO.
Análisis básico
Ya teniendo los datos listos, podemos hacer análisis adicionales a lo que se presenta en el reporte (desde la página 17). Particularmente quiero explorar los textos y alguna cosa que se me vaya ocurriendo.
data %>%count(dependencia, sort = T) %>%top_n(10) %>%xtable() %>%print(type ="html")
Selecting by n
dependencia
n
1
Sistema de Transporte Colectivo
459
2
Jefatura de Gobierno de la Ciudad de México
398
3
Secretaría de Obras y Servicios
196
4
Secretaría de Gestión Integral de Riesgos y Protección Civil
142
5
Fiscalía General de Justicia de la CDMX
66
6
Secretaría de Movilidad
62
7
Secretaría de la Contraloría General
56
8
Secretaría de Gobierno
49
9
Secretaría de Administración y Finanzas
37
10
Comisión Ejecutiva de Atención a Víctimas de la Ciudad de México
35
data %>%count(organo_de_gobierno, sort = T) %>%xtable() %>%print(type ="html")
organo_de_gobierno
n
1
Administración Pública Central
998
2
Organismos desconcentrados, descentralizados, paraestatales y auxiliares
563
3
Órganos Autónomos
109
4
Poder Legislativo
47
5
Sindicatos
41
6
Alcaldías
36
7
Partidos Políticos
6
8
Poder Judicial
5
9
Fideicomisos y fondos públicos
2
Es evidente, que el Sistema de Transporte Colectivo (metro) iba a ser el sujeto obligado con más solicitudes de información pública sobre el tema.
# data %>%# count(respuesta)
De las 1,807 solicitudes, hay 281 grupos de respuestas, y si empezamos a revisar vemos que los grupos se pueden reducir… No estaba en el plan, pero estaría interesante para revisar. Dado que se ve gigantesco, chéquenlo con calma en su equipo. Pero, a bote pronto, hay 600 solicitudes sin respuesta (33%), 444 (25%) se contestaron vía infomex (descanse en paz) o por la Plataforma Nacional de Transparencia (pero no sabemos que se respondió); 188 (10%) dijeron que la solicitud le corresponde a otro ente OJO este es el texto directo sin adornos abogadiles (nada contra ustedes; sin embargo, nadie entiende como escriben). 79 (4%) fueron prevenidas (esto significa que a las personas servidoras públicas no les quedó clara la, o las, preguntas y le piden más información a la persona solicitante) y 51 (3%) se declararon incompetentes para responder y 26 (1%) se reservaron, esto significa que es información que poseen las instituciones y que por motivos de seguridad no puede ser entregada por un tiempo determinado.
Después de todo ese rollo, falta 26% de las solicitudes… que están en abogañol o que no se puede clasificar en un ratito. Si quieren ayuda envíenme un DM Las cifras las fui sacando de medio leer los resultados en una hoja de Excel :P
dias <- data %>%mutate(dia =date(fecha_de_ingreso)) %>%count(dia) %>%ggplot(aes(x = dia, y = n)) +geom_line() +labs(x ="", y ="",title ="Solicitudes por día" ) +theme_classic()ggplotly(dias)
El pico de solicitudes está el 5 de junio de 2022. En blogs pasados, específicamente en el análisis de “Días sin ti” utilicé gráficas interactivas, donde podías hacer zoom y te daba información básica de la observación, aquí utilizo la misma técnica.
Análisis de texto
Algo que no va a ser muy riguroso es el análisis de texto, por qué? Porque las solicitudes de información se caracterizan por ser texto libre y contener, en algunos casos, datos personales. Si bien este dataset tiene testados los datos personales, estos son reemplazados por asteriscos. Aun así, espero encontrar algo interesante.
Esto ya se la saben, limpieza de textos para tener solo palabras. Ahora, mientras redactaba esto, salieron palabras comunes que son demasiado obvias: metro, 12, línea, sistema, transporte, colectivo, etc. Por eso las filtro antes
texto %>%count(palabra, sort = T) %>%top_n(20)
Selecting by n
palabra n
1 empresa 1174
2 mayo 1067
3 dnv 886
4 mantenimiento 759
5 copia 717
6 informe 652
7 tramo 610
8 construccion 598
9 fecha 569
10 dictamen 543
11 colapso 539
12 accidente 508
13 gobierno 493
14 contrato 451
15 expedientes 448
16 obra 444
17 respecto 432
18 ocurrido 431
19 documentos 417
20 trenes 415
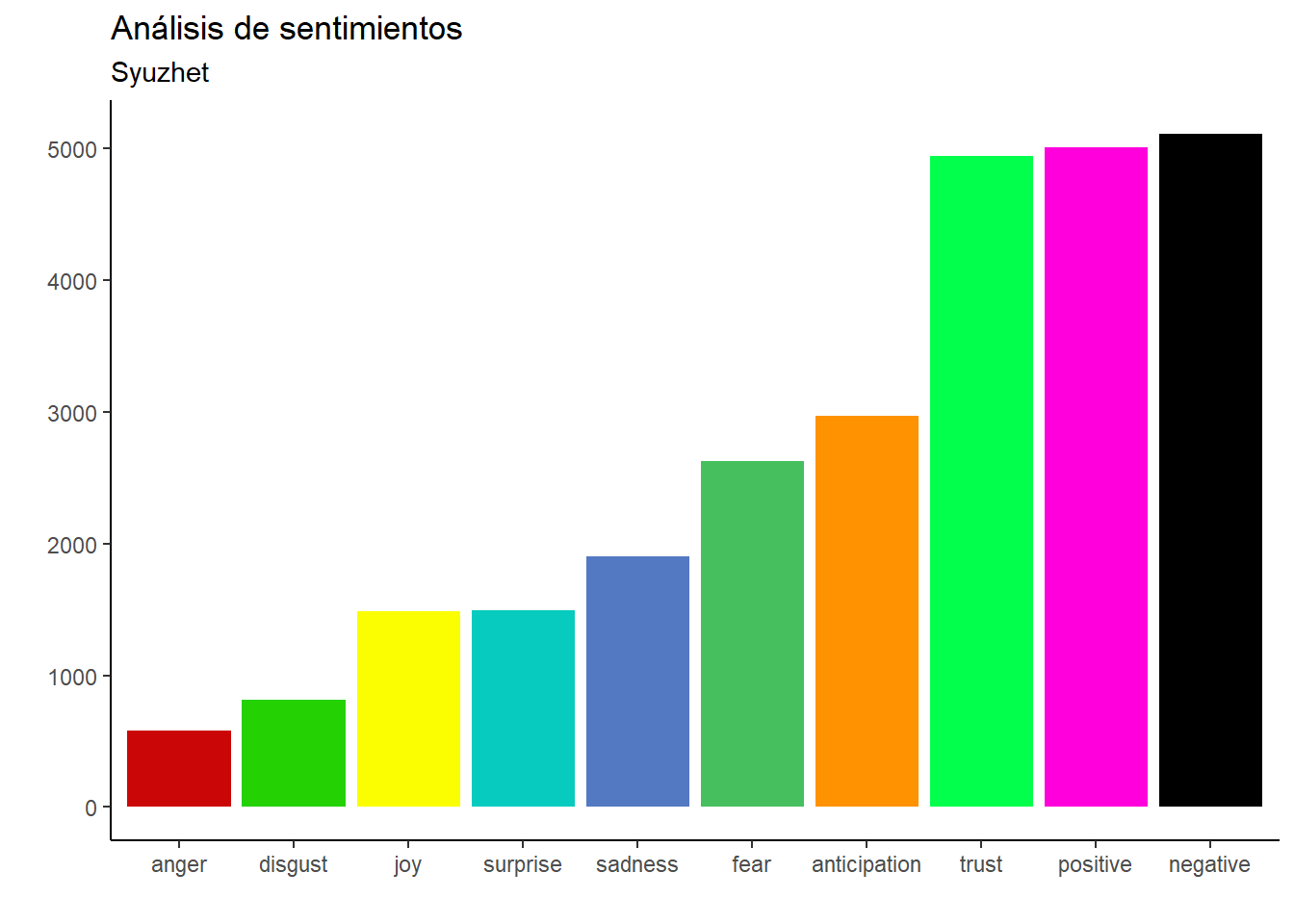
Ahora, el análisis de sentimiento con Syuzhet, que es unir dos dataframes.
texto_nrc <-get_nrc_sentiment(char_v = texto$palabra, language ="spanish")texto_fin <-bind_cols(texto, texto_nrc)
Resalta que la mayoría de las palabras tienen un sentido negativo… Lo cual tiene cierta lógica, uno no pide información porque ande feliz. Por otro lado, también es sorprendente que no haya tantas palabras relacionadas con el enojo… Si quieren entender que está pasando detrás, vean la documentación de Syuzhet.
Si a alguien se le ocurre algo más que se pueda hacer, hágamelo saber. Por ahora, creo que esto nos da en qué pensar. Si bien es limitado el número de variables en estas bases de datos, mientras más análisis se realicen con esta información se podrán aprovechar mejor. O bien, nos daremos cuenta de que información hace falta y se podría solicitar que se libere.
Muchas gracias a Zule por su lectura y recomendaciones para que este texto sea más entendible.