No quieres copiar y pegar páginas donde están los datos y luego pasar horas limpiandolos en excel? Copia y pega este script para automatizar aunque sea un poco el proceso
code
visualization
politics
spanish
Author
David Humberto Jiménez S.
Published
November 1, 2021
Modified
November 30, 2023
¡Holi!
He estado perdido, igual y no lo notaron, pero estoy vivo. Dos borradores de post, que están pendientes, un montón de trabajo, trámites de la escuela y demás cosas en el camino, I’m back.
El otro día me pidieron hacer una relación de otro proyecto en el que estaba colaborando Análisis de las elecciones federales 2021 y pensé: “a, pues eso sale en chinga con R”, pero hace mucho no hago scraping, no pude y terminé haciéndolo a mano.
Para que no les pase lo que a mí, voy a explicarles todo lo que sé esperando que no vuelvan a cambiar la library y lo que vean aquí no funcione (como me pasó en los 3 tutoriales de hace menos de 2 años que revisé).
library(purrr)
Warning: package 'purrr' was built under R version 4.2.3
library(rvest)
Warning: package 'rvest' was built under R version 4.2.3
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(stringr)
Warning: package 'stringr' was built under R version 4.2.3
Entonces, lo primero siempre es cargar las libraries que vamos a utilizar. El paquete nuevo es rvest que literalmente se llama así por harvest para “cosechar” los datos de una página web. Todos los paquetes de R son superñoños, por si no se habían dado cuenta.
Scrapping!
url <-"https://analisiselectoral2021.juridicas.unam.mx/publicaciones?page="dada <-paste0(url, "0") # enlace con las publicciones más recientes
Como ya revisé cuántas páginas había en ese portal, sé que van del 0 al 6. Sigo buscando un método para no tener que contarlo a mano, así que avísenme.
Ahora, lo que hay que hacer es entender cómo se organiza una página web. Hay personas mucho más hábiles que yo para eso, yo solo les sugiero que en la página que seleccionen den clic derecho en cualquier lado y seleccionen inspeccionar. Esto funciona si utilizas chrome.
Ahora, si ustedes como yo no tienen idea de páginas web, html y CSS… solo tienen que buscar lo que diga class y probar.
titulos <-read_html(dada) %>%# Con esta función hacemos que R "lea" la páginahtml_nodes(".titulo-publicacion-l") %>%# Aquí seleccionamos el "nodo" o clase que queremos recuperarhtml_text() %>%# y con esto lo convertimos a textoas_tibble() %>%rename(titulo = value)
Este es un vector de texto, ¿se acuerdan de las primeras entradas y como una serie de vectores acomodados crean un dataframe? Pues aquí es donde rinde sus frutos entender la diferencia. Además, el scrapping funciona por posiciones, así que si la página está lógicamente construida podemos extraer sin problemas la información necesaria
autor <-read_html(dada) %>%html_nodes(".autores") %>%html_text() %>%as_tibble() %>%rename(autor = value)
Entonces los títulos ya están, los autores ya están, pero qué pasa si quiero los enlaces a las notas? Bueno, es un poco más complicado, y no es tan general, pero puedes seleccionar más de un nodo y en lugar del texto, los atributos.
Tachán!! Listo, un scrap sencillo pero poderoso. Sin embargo, hay muchas páginas. Cómo aún no me sé una manera de contarlas automáticamente, pero sé que son 7 páginas de publicaciones, pues vamos a hacer un loop, o mejor dicho un map.
lista <-map( url,~paste0(.x, seq(0, 6, by =1))) %>%unlist()lista
El primero que necesitamos es bastante sencillo, tenemos la dirección lista para pegarle los números. Como no la vamos a hacer a mano, hay que hacer algo. Yo opté por crearlo con un map, para que luego se convierta en lista y al momento de hacerle el unlist se convierte en caracteres. La otra opción sería crear un data frame con una columna de número de 0 al 6, luego pegar la columna url, pegar ambas, quitar lo que no sirve o seleccionar la nueva columna y transformarla a vector o en su defecto, utilizar dataframe$columna.
Si se les ocurre otra manera, avísenme, que siempre se aprende algo nuevo.
final <-cbind(titulos, autores, fechas, enlaces) %>%mutate(enlaces =paste0(detalle, enlaces) )head(final)
titulo
1 La forma de una tensión: democracia directa, ciudadanos y partidos
2 La crisis del modelo de comunicación política propiciada desde la presidencia.
3 Estudia, macho…
4 Aprobación de los Lineamientos para la Revocatoria de Mandato
5 El “diezmo” de Texcoco
6 La complejidad de la paridad en la integración del Congreso de la Ciudad de México
autor fecha
1 Nicolás Loza 2021-10-14
2 María Marván Laborde 2021-10-11
3 Nicolás Loza 2021-10-07
4 Flavia Freidenberg 2021-10-05
5 Guadalupe Salmorán Villar 2021-10-04
6 Karolina Gilas 2021-10-04
enlaces
1 https://analisiselectoral2021.juridicas.unam.mx/detalle-publicacion/157
2 https://analisiselectoral2021.juridicas.unam.mx/detalle-publicacion/155
3 https://analisiselectoral2021.juridicas.unam.mx/detalle-publicacion/153
4 https://analisiselectoral2021.juridicas.unam.mx/detalle-publicacion/151
5 https://analisiselectoral2021.juridicas.unam.mx/detalle-publicacion/149
6 https://analisiselectoral2021.juridicas.unam.mx/detalle-publicacion/147
Y listo!!! Tenemos una base de datos con los nombres de las publicaciones, autores, fechas y enlaces.
Pero… creo que le podemos sacar más jugo a esto… Por ejemplo, que tal si de una vez recuperamos los textos de las publicaciones? Que por qué? Por la gloria de Satán! Digo, porque podemos utilizar nuestras herramientas de análisis de texto y ver si hay cosas interesantes de esta manera, o hay que leer todo el texto para entenderlo.
Scrapping y textos
Entonces, ¿cómo le hacemos? Ya tenemos la lista de enlaces
publicaciones <-map( final$enlaces,~read_html(.x) %>%html_nodes(".col-12") %>%# Esta es la clase que buscamoshtml_text() %>% .[2] %>%# solo necesitamos el segundo elemento de la lista que arrojaas_tibble() %>%rename(texto = value) %>%mutate(enlaces = .x)) %>%# aunque el scrapping funciona por posiciones, a veces me da miedo y le genero identificadores para unir los DFbind_rows()final <-left_join(final, publicaciones)
Joining with `by = join_by(enlaces)`
Y con eso, hemos leído las 70 publicaciones. Pero, hay un pequeño problema: aparece el título, tema, autor, fecha, un disclaimer y una leyenda para descargar un archivo. Esto porque el scrapping depende mucho de como esté armada la página. Como utilizamos una clase que agrupa todo el texto, se incluyen estos elementos.
library(tm)
Warning: package 'tm' was built under R version 4.2.3
Loading required package: NLP
library(tidyr)
Warning: package 'tidyr' was built under R version 4.2.3
library(ggplot2)
Attaching package: 'ggplot2'
The following object is masked from 'package:NLP':
annotate
library(syuzhet)
Warning: package 'syuzhet' was built under R version 4.2.3
library(tidytext)
Warning: package 'tidytext' was built under R version 4.2.3
library(lubridate)
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
Igual que en un par de post anteriores, este, este y este, necesitamos estas dos libraries para analizar los textos.
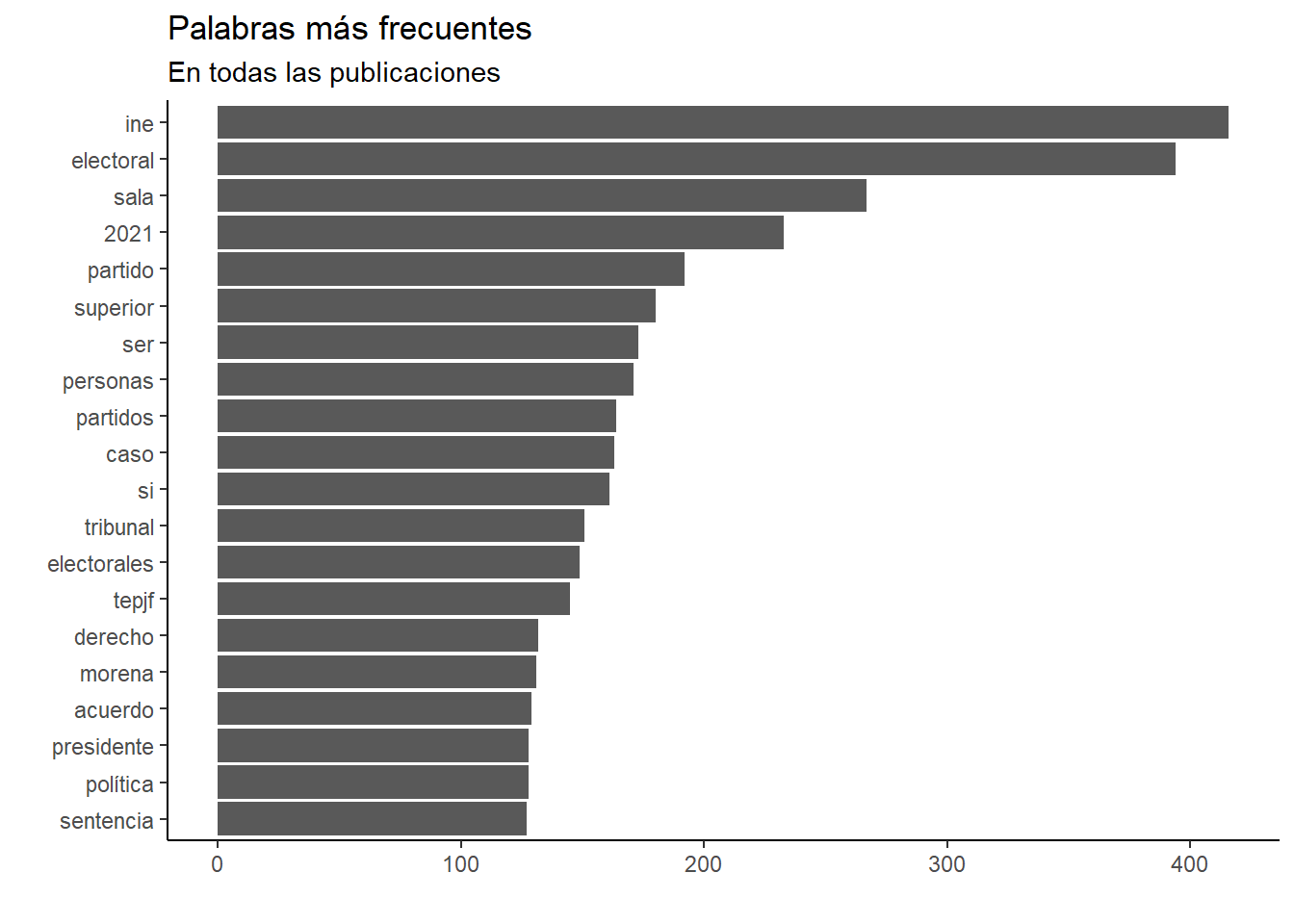
final %>%unnest_tokens(palabra, texto) %>%filter(!palabra %in%stopwords("es")) %>%count(palabra, sort = T) %>%mutate(palabra =reorder(palabra, n)) %>%top_n(20) %>%ggplot(aes(x = n, y = palabra)) +geom_bar(stat ="identity") +theme_classic() +labs(x ="", y ="",title ="Palabras más frecuentes",subtitle ="En todas las publicaciones" )
Selecting by n
Como no es ninguna sorpresa, “INE” y “electoral” son las palabras más frecuentes en todas las publicaciones. Pero, tenemos manera de revisar el top 10 de cada autor. Sin embargo, antes, vamos a ver cuantas publicaciones tiene cada autor y las publicaciones por mes, nomás porque sí.
final %>%count(autor, sort = T)
autor n
1 Karolina Gilas 9
2 Flavia Freidenberg 8
3 Juan Jesús Garza Onofre 8
4 Luz María Cruz Parcero 7
5 Nicolás Loza 7
6 Roberto Lara Chagoyán 7
7 Guadalupe Salmorán Villar 6
8 María Marván Laborde 6
9 Hugo Alejandro Concha Cantú 4
10 Ximena Medellín 4
11 Horacio Vives Segl 3
12 Javier Martín Reyes 1
final %>%mutate(fecha =as_date(fecha)) %>%group_by(mes =month(fecha)) %>%count()
# A tibble: 8 × 2
# Groups: mes [8]
mes n
<dbl> <int>
1 3 5
2 4 12
3 5 8
4 6 16
5 7 7
6 8 11
7 9 5
8 10 6
Resulta interesante que el máximo de publicaciones es 9 y el mínimo es 1. Además, el mes con mayor número de notas fue junio.
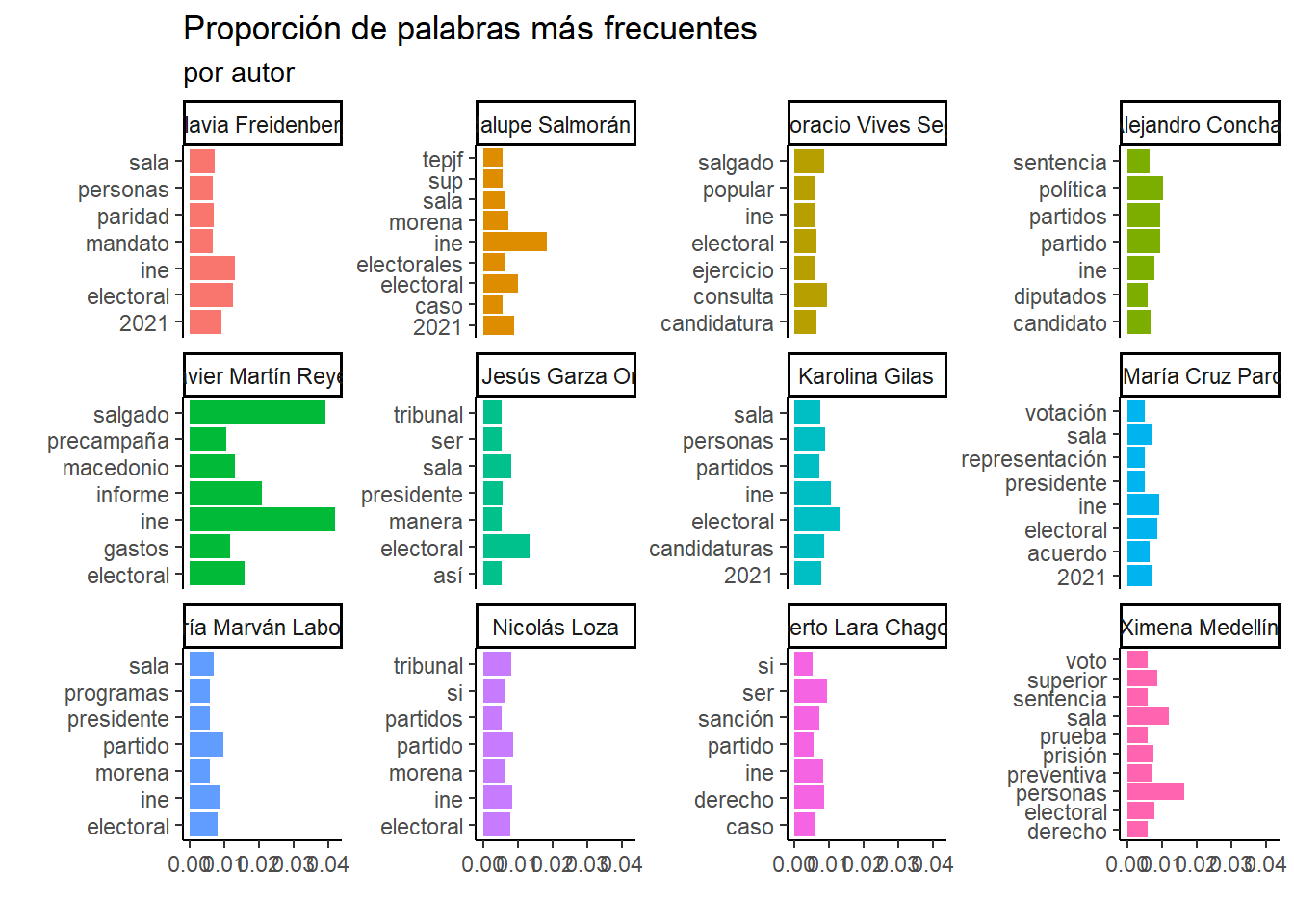
final %>%unnest_tokens(palabra, texto) %>%filter(!palabra %in%stopwords("es")) %>%count(autor, palabra, sort = T) %>%group_by(autor) %>%mutate(prop = n /sum(n)) %>%top_n(7) %>%ggplot(aes(x = prop, y = palabra, fill = autor)) +facet_wrap(. ~ autor, scales ="free_y") +geom_bar(stat ="identity") +theme_classic() +theme(legend.position ="blank") +labs(x ="", y ="",title ="Proporción de palabras más frecuentes",subtitle ="por autor" )
Selecting by prop
Ahora bien, la gráfica anterior era solo por palabras más frecuentes. Pero, como sabemos hay autoras que tuvieron más publicaciones. Por esta razón utilicé el top 10 de palabras más frecuentes como proporción del total de palabras de cada autora. El outlier es Javier Martín Reyes porque tiene una sola publicación.
Y estas son las cosas sencillas que podemos lograr con un web scrapping y las herramientas que vamos acumulando. Por ejemplo, análisis de sentimientos! No hay que olvidar que la función para esto tarda más de lo normal. Entonces no desesperen.
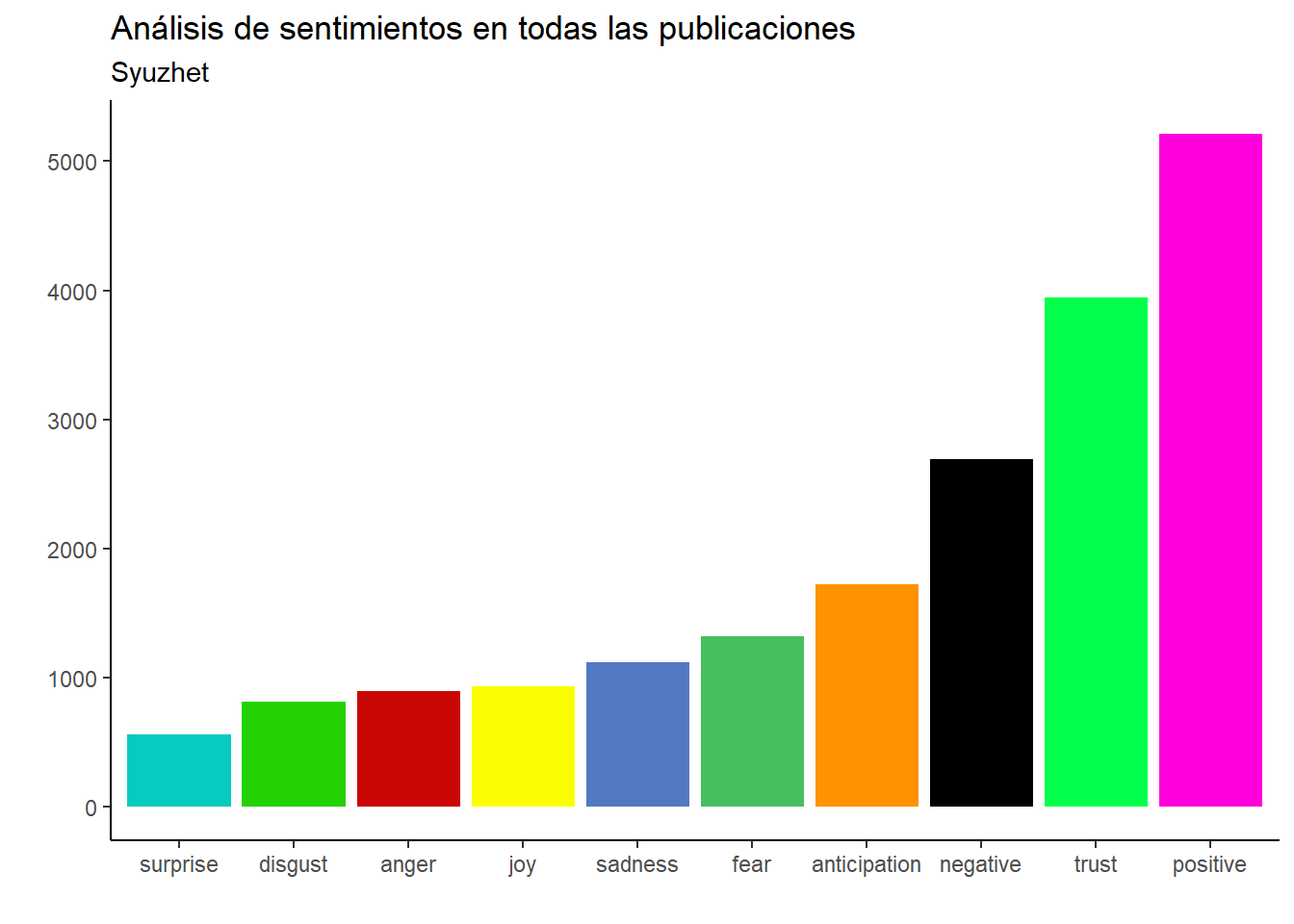
text <- final %>%unnest_tokens(palabra, texto) %>%filter(!palabra %in%stopwords("es"))text_nrc <-get_nrc_sentiment(char_v = text$palabra, language ="spanish")bind_cols(text, text_nrc) %>%pivot_longer(cols =6:15 ) %>%group_by(name) %>%summarise(total =sum(value)) %>%ungroup() %>%mutate(name =reorder(name, total)) %>%ggplot(aes(x = name, y = total, fill = name)) +geom_bar(stat ="identity") +scale_fill_manual(breaks =c("disgust", "surprise", "anger", "joy", "anticipation", "fear", "sadness", "trust", "positive", "negative"),values =c("#24D204", "#06CBBE", "#CB0606", "#FBFE00", "#FF9200", "#46BF5F", "#5479C3", "#01FF4C", "#FF00DC", "#000000") ) +theme_classic() +labs(title ="Análisis de sentimientos en todas las publicaciones",subtitle ="Syuzhet",x ="", y ="" ) +theme(legend.position ="blank")
Todo apunta a que las investigadoras involucradas en este proyecto confían en las decisiones tomadas por el Tribunal Electoral y el INE. Después de todo, son los organismos que deciden la política electoral en la práctica. A pesar de todo, aún hay confianza en las instituciones. Cualquier cosa mándenme un DM